前言
最近用OC、C++混编的形式实现了一个库,对性能要求较高的地方用了C++实现。编码过程中遇到一个问题,基础类型变量的线程安全问题。为了保证性能,采用了std::atomic 来保证了线程安全。由此引发了几个思考:基础变量的写和读操作不是原子性的吗?为啥要加锁?为什么 std::atomic 的性能比GCD锁性能高?std::atomic 类型的变量的操作都涉及的内存顺序是什么?为啥会有这个概念?OC 中的 atomic 为啥一般不使用?
本文主要针对上述的这几个疑问进行讲解,分为两部分:
- 第一部分:内存相关的基础知识
- 缓存一致性
- 内存屏障
- 内存重排
- 内存顺序
- 第二部分
- 基础变量的写和读操作不是原子性的吗?为啥要加锁?
- 为什么 std::atomic 的性能比GCD锁性能高
- OC 中的atomic为啥一般不使用?
第一部分:内存相关的基础知识
缓存一致性
CPU在摩尔定律(CPU集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍)的指导下以每18个月翻一番的速度在发展,然而内存和硬盘的发展速度远远不及CPU。然而CPU的高度运算需要高速的数据。为了解决这个问题,CPU厂商在CPU中内置了少量的高速缓存以解决I\O速度和CPU运算速度之间的不匹配问题。目前的多核处理器一般都是多CPU多级缓存:

在CPU访问存储设备时,无论是存取数据抑或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理。
时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。比如循环、递归、方法的反复调用等。
空间局部性(Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。比如顺序执行的代码、连续创建的两个对象、数组等。
所以CPU都带有高速缓存的CPU,其执行计算的流程:
- 程序以及数据被加载到主内存
- 指令和数据被加载到CPU的高速缓存
- CPU执行指令,把结果写到高速缓存
- 高速缓存中的数据写回主内存
如何保证多个缓存一致性是保证原子性很重要的一点。比如如果没有保证一致性,cpu1读取的变量和cpu 2读取的同样变量值不一样,原子性肯定不能保证了。为了保证缓存内部数据的一致,不让系统数据混乱,就有了缓存一致性即MESI协议。它很好的描述了Cache和Memory(内存)之间的数据关系(数据是否有效,数据是否被修改)。
在MESI协议中,每个Cache line有4个状态,它们分别是:
- M 修改 (Modified)
- 该 Cache line 有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache中。
- 缓存行必须
+发送ivalid消息到
- 时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。且
- E 独享、互斥 (Exclusive)
- 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。
- 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。
- S 共享 (Shared)
- 该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中。
- 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。
- I 无效 (Invalid)
+ 该Cache line无效。

内存屏障
缓存一致性的保证(状态传递+切换)会阻塞处理器,这会降低处理器的性能。应为这个等待远远比一个指令的执行时间长的多。为了避免这种CPU运算能力的浪费,Store Bufferes被引入使用。处理器把它想要写入到主存的值写到缓存,然后继续去处理其他事情。当所有失效确认(Invalidate Acknowledge)都接收到时,数据才会最终被提交。这么做有两个风险
- 就是处理器会尝试从存储缓存(Store buffer)中读取值,但它还没有进行提交。这个的解决方案称为Store Forwarding,它使得加载的时候,如果存储缓存中存在,则进行返回。
- 这个就是导致多线程执行的时候,会出现A线程写,A线程本身能感知到,因为写的内存暂时存锤在 store buffers,然后B线程感知不到,即A的修改对B不可见。
- 保存什么时候会完成,这个并没有任何保证。
处理器提供了两个API解决这个问题,这就是内存屏障(Memory Barriers)。
- 写屏障 Store Memory Barrier(a.k.a. ST, SMB, smp_wmb)是一条告诉处理器在执行这之后的指令之前,应用所有已经在存储缓存(store buffer)中的保存的指令。
- 读屏障Load Memory Barrier (a.k.a. LD, RMB, smp_rmb)是一条告诉处理器在执行任何的加载前,先应用所有已经在失效队列中的失效操作的指令。
store buffer 的优势,由于目前都是多级缓存的结构,store 一个数据到真正的存储到内存是一个比较耗时的操作,store buffer 存在的意义是,当前线程不需要等待store的内容同步到内存,只需要同步到store buffer 既可以继续执行。例如下面代码,不需要等待A同步到内存,就可以继续执行print B,这个叫读写指令重排,对当前线程无影响,对多线程有影响。
A = 1;
printf(A)
内存重排
内存重排是指程序在实际运行时对内存的访问顺序和代码编写时的顺序不一致,主要是为了提高运行效率。分别是硬件层面的 CPU 重排 和软件层面的 编译器重排。
编译器重排
X = 0
for i in range(100):
X = 1
print X
优化成
X = 1
for i in range(100):
print X
对统一线程没影响,但是多线程会有影响。
CPU重排
用户写下的代码,先要编译成汇编代码,也就是各种指令,包括读写内存的指令。CPU 的设计者们,为了榨干 CPU 的性能,无所不用其极,各种手段都用上了,你可能听过不少,像流水线、分支预测等等。其中,为了提高读写内存的效率,会对读写指令进行重新排列,这就是所谓的 内存重排,英文为 Memory Reordering。上面说的读写指令重排也是CPU重排的一种。

内存顺序 Memory Order
为什么需要 Memory Order
如果不使用任何同步机制(例如 mutex 或 atomic),在多线程中读写同一个变量,那么,程序的结果是难以预料的。简单来说,编译器以及 CPU 的一些行为,会影响到程序的执行结果:
- 即使是简单的语句,C++ 也不保证是原子操作。
- CPU 可能会调整指令的执行顺序,即内存重排
- 在 CPU cache 的影响下,一个 CPU 执行了某个指令,不会立即被其它 CPU 看见。
最常见的同步机制就是std::mutex和std::atomic。然而,从性能角度看,通常使用std::atomic会获得更好的性能。
Memory Order
std::memory_order 的几个选择:
+ std::memory_order_relaxed:仅保持变量自身读写的相对顺序
+ std::memory_order_consume:依赖于该读操作的后续读写,不能往前乱序;另一个线程上std::memory_order_release之前的相关写序列,在std::memory_order_consume同步之后对当前线程可见
+ std::memory_order_acquire:之后的读写不能往前乱序;另一个线程上std::memory_order_release之前的写序列,在std::memory_order_acquire同步之后对当前线程可见
+ std::memory_order_release:之前的读写不能往后乱序;之前的写序列,对使用std::memory_order_acquire/std::memory_order_consume同步的线程可见
+ std::memory_order_acq_rel:两边的读写不能跨过该操作乱序;写序列仅在同步线程之间可见
+ std::memory_order_seq_cst:两边的读写不能跨过该操作乱序;写序列的顺序对所有线程相同(所有线程包括自己,即对写对所有线程均可见)
std::atomic 提供了4种 Memory Order
- Relaxed ordering
- Release-Acquire ordering
- Release-Consume ordering
- Sequentially-consistent ordering
下面对这几种顺序分别进行介绍
Relaxed ordering
在这种模型下,std::atomic的load()和store()都要带上memory_order_relaxed参数。Relaxed ordering 仅仅保证load()和store()是原子操作,除此之外,不提供任何跨线程的同步。但是性能比较高,如果没有什么特殊的要求,建议用这个。下面例子可能出现r1 == r2 == 42
std::atomic<int> x = 0; // global variable
std::atomic<int> y = 0; // global variable
Thread-1: Thread-2:
r1 = y.load(memory_order_relaxed); // A r2 = x.load(memory_order_relaxed); // C
x.store(r1, memory_order_relaxed); // B y.store(42, memory_order_relaxed); // D
Release-Acquire ordering
在这种模型下,store()使用memory_order_release,而load()使用memory_order_acquire。这种模型有两种效果:
- 第一种是可以限制 CPU 指令的重排:
- 在store()之前的所有读写操作,不允许被移动到这个store()的后面。
- 在load()之后的所有读写操作,不允许被移动到这个load()的前面
- 第二种可见性约束
- 假设 Thread-1 store()的那个值,成功被 Thread-2 load()到了,那么 Thread-1 在store()之前对内存的所有写入操作,此时对 Thread-2 来说,都是可见的。
Release-Consume ordering
在这种模型下,store()使用memory_order_release,而load()使用memory_order_Consume。这种模型有两种效果:
- 第一种是可以限制 CPU 指令的重排:
- 在store()之前的所有读写操作,不允许被移动到这个store()的后面。
- 在load()之后的所有读写操作,不允许被移动到这个load()的前面
- 第二种可见性约束
- 假设 Thread-1 store()的那个值,成功被 Thread-2 load()到了,那么 Thread-1 在store()之前对内存的相关写入操作,此时对 Thread-2 来说,是可见的。
Sequentially-consistent ordering
在这种模型下,仍然有两种效果:
- 第一种是可以限制 CPU 指令的重排:
- 两边的读写不能跨过该操作乱序,即前面的不能倒后面,后面的不能到前面
- 第二种可见性约束
- std::memory_order_seq_cst:两边的读写不能跨过该操作乱序;
第二部分
基础变量的写和读操作不是原子操作吗?为啥要加锁?
什么是原子操作?
原子操作:不可被中断的一个或一系列操作。 计算机中的原子操作一般有两种
- 基本的内存操作的原子性
- [标准库头文件
](https://zh.cppreference.com/w/cpp/header/atomic)提供的稍微复杂一些的原子操作(可能不是一个cpu指令,多个cpu指令,跨多 cahce line,需要一些机制加硬件完成)
在多核多处理器的情况下,上述的原子操作是如何实现的呢?
原子操作是如何保证的
基本前提
处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存当中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。
扩展一点:32 (64)位机器从内存读写对齐后的32(64)位变量,或小于32(64)位的变量 也会保证原子性。
注意这里是保证对内存操作的原子性,不是对缓存。为啥强调不是对缓存呢?多核CPU有多个缓存,那么即使操作一字节的内容也不能保证原子性了,因为多个CPU多个缓存,可以同时更改,在写入内存的话,就出问题了。
总线锁
所谓总线锁就是使用处理器提供的一个 LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住, 那么该处理器可以独占使用共享内存。但总线锁定把 CPU 和内存之间通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大。所以还有缓存一致性
小结
处理器结合基本前提(保证访问内存读取对应字节的原子不可分割)和
- 若在一个cache line 上用缓存一致性实现原子
- 若不在一个cache line,则用总线锁实现原子性
- 内存模型
实现了一些原子操作,供上层使用。
由于缓存一致性效率高一些,当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行,处理器会调用总线锁定。
OS根据这些原子操作就能够实现锁,在基于锁,就能实现各种各样的同步机制(信号量、消息等等)。
这些原子操作指示处理器提供了原子操作的能力,但是我们写的代码大部分不是原子操作,但是又有时序性和同步性的要求,这就要用到了锁。
为什么 OC 编程中我们没有考虑过这些
为什么我们在写代码的时候没有考虑到内存一致性+内存屏障等问题呢?
- 一方面,如果我们写的代码是在同一个线程执行的,则不需要考虑内存一致性+内存屏障,因为一直使用的是一个cpu的cache和storebuffer,不存在这些问题
- 如果是写的代码涉及到多线程,iOS 提供的GCD等操作已经对内存屏障等进行了封装,底层调用,保证每次对应线程拿取的是内存最新的内容。也就是帮我们封装好了。
- 在 iOS 开发中,我们常使用 GCD 作为多线程开发的框架,这类 High Level 的多线程模型本身已经提供好了天然的内存屏障来保证指令的执行顺序
我们写代码主要注意线程见同步和时序性就行,而这些一般靠锁实现
那遇到的基础类型读写是否要加锁
遇到的问题:一个64位全局变量,一个多个线程读写 是否要加锁呢?我们分析下一个全局变量到底需不需要加锁保证原子性
- 如果是单线程操作肯定没有必要加锁
- 多线程
- 一个线程写一个线程读
- 若出现这种情况主线程执行全局变量写操作,之后马上异步到其他线程执行读操作,假设这个线程是其他cpu,由于store buffer 原因肯能会导致读取到旧值
- 若两条线程并行,然后内存没有读取或者是32位机器,导致写这个32位的全局变量需要两次,若没有保证原子性,则可能出现:写一半——另一线程读——该线程继续写,导致读取到错的值
- 对线程读写
- 根据一线程读一线程写,多线程读写就更可能出问题了。
- 一个线程写一个线程读
因此,需要加锁保证原子性。但是我们加锁是为了保证原子性,如果有别的方案可以实现原子读写一个变量,可以不用加锁,这就涉及到了C++ 的std::atomic
为什么 std::atomic 的性能比GCD锁性能高
互斥锁
上面说的问题,如果用锁解决,我们一般会用互斥锁来解决,这里简单分析下互斥锁的原理。
上面也说了锁的实现基于来处理器提供的原子操作,基本原理如下:
pthread_mutex_lock:
atomic_dec(pthread_mutex_t.value);
if(pthread_mutex_t.value!=0)
futex(WAIT)
else
success
pthread_mutex_unlock:
atomic_inc(pthread_mutex_t.value);
if(pthread_mutex_t.value!=1)
futex(WAKEUP)
else
success
- 上面代码中的
atomic_dec就是处理器提供的原子操作,通过总线锁+缓存一致性实现。一般来说,thread_mutex_t.value是一个一个对齐后的整型变量,因此改原子性的实现不需要用总线锁,只需要缓存一致性就可以实现。 - 为什么加锁的代价较大呢?
- 一个锁会被翻译成多个cpu指令
- 存在线程WAIT行为
- 光是在内核里睡眠/唤醒一下,就至少是微秒级的时间开销,更别说各种额外的调用、封装、判断了。
futex(&lock, FUTEX_WAIT... )退避进入阻塞等待直到 lock 值变化时唤醒。futex在设计上期望做到如果无争用,则可以不进内核态,不进内核态的 fast path 的开销等价于 atomic 判断。内核里维护按地址维护一张 wait queue 的哈希表,发现锁变量值的变化(解锁)时,唤醒对应的 wait queue 中的一个 task。wait queue 这个哈希表的槽在更新时也会遭遇争用,这时继续通过 spin lock 保护。
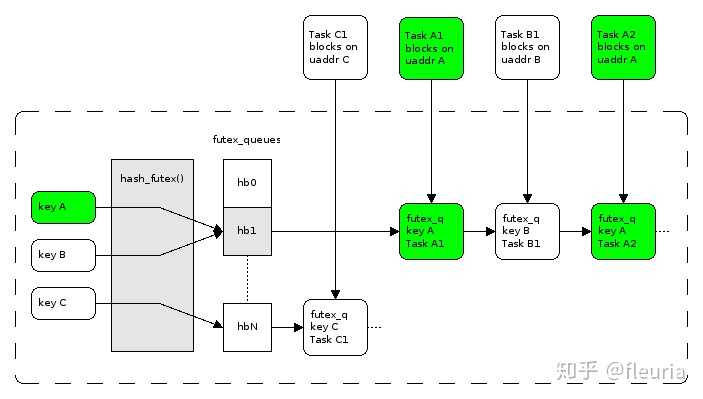
为什么使用std::atomic
因为std::atomic的性能比互斥锁高,原因呢? 上面介绍了为啥互斥锁等锁会慢,这里注意讲一下为什么 std::atomic 快
- std::atomic 会直接使用处理器提供的原子操作;
- 且 std::atomic 会根据应用的对象是基础类型还是自定义对象,决定是无锁实现还是有锁 + 比如 基础类型,会通过缓存一致性实现,效率更高 + 自定义对象,涉及多个 cache line,肯能要总线锁
- 锁的机制也类似,除去上面说的额外的哪些耗时内容,也会在缓存一致性+总线锁进行选择的
- C++的std::atomic与体系结构中多核内存模型/缓存一致性协议(监听 目录协议)有什么关系?映射关系。C++11当中的std::atomic就是对体系结构中多核内存模型/缓存一致性协议的一种定义。在编译的时候,由编译器根据目标硬件平台实际的多核内存模型/缓存一致性协议决定最终生成的指令序列。std:atomic 似乎和缓存一致性协议功能上重复了前者的范围更大,包括内存模型和缓存一致性两个方面
OC 中的atomic为啥一般不使用?
atomic 修饰符原理
- nonatomic set get实现
- (void)setCurrentImage:(UIImage *)currentImage {
if (_currentImage != currentImage) {
[_currentImage release];
_currentImage = [currentImage retain];
// do something
}
}
- (UIImage *)currentImage {
return _currentImage;
}
- atomic set get实现
- (void)setCurrentImage:(UIImage *)currentImage {
@synchronized(self) {
if (_currentImage != currentImage) {
[_currentImage release];
_currentImage = [currentImage retain];
// do something
}
}
}
- (UIImage *)currentImage {
@synchronized(self){
return _currentImage;
}
}
为什么一般不用
- 在iOS中使用同步锁的开销比较大, 这会带来性能问题。一般情况下并不要求属性必须是“原子的”,因为这并不能保证“线程安全”(thread safety),若要实现“线程安全”的操作,还需采用更为深层的锁定机制才醒。
- 多条线程同时工作的情况下,通过运用线程锁,原子性等方法避免多条线程因为同时访问同一快内存造成的数据错误或冲突.
- 当线程A进行写操作,这时其他线程的读或者写操作会因为该操作而等待。当A线程的写操作结束后,B线程进行写操作,然后当A线程需要读操作时(期待A线程的读写是原子的),却获得了在B线程中的值,这就破坏了线程安全,如果有线程C在A线程读操作前release了该属性,那么还会导致程序崩溃。所以仅仅使用atomic并不会使得线程安全,我们还要为线程添加lock来确保线程的安全。
- 当使用atomic时,虽然对属性的读和写是原子性的,但是仍然可能出现线程错误:当线程A进行写操作,这时其他线程的读或者写操作会因为等该操作而等待。当A线程的写操作结束后,B线程进行写操作,所有这些不同线程上的操作都将依次顺序执行——也就是说,如果一个线程正在执行 getter/setter,其他线程就得等待。如果有线程C在A线程读操作之前release了该属性,那么还会导致程序崩溃。所以仅仅使用atomic并不会使得线程安全,我们还要为线程添加lock来确保线程的安全。atomic所说的线程安全只是保证了getter和setter存取方法的线程安全,并不能保证整个对象是线程安全的。
- 既然atomic 不是线程安全,为啥还会有改关键字呢?
- atomic 更准确的说应该是读写安全,但并不是线程安全的,因为别的线程还能进行读写之外的其他操作。线程安全需要开发者自己来保证